




从流量到入站:LTD方法论与营销枢纽如何让企业抓住业绩翻番的新机遇
2024-03-06 14:13:05

LTD364次升级 | 通用站点集成企业微信客服、AI智能体 • 编辑器代码组件升级,代码模块使用更便捷
2026-03-09 00:00:00

不能放弃思考,任由平台来给我们定义「私域」这个概念
2022-07-05 18:18:42

福建利来国际物流有限公司官网上线 | LTD物流运输行业案例分享
2022-10-28 17:27:07

关掉噪音只谈赚钱:站点智能了,不懂IT技术也能全球做生意
2025-08-29 11:56:35

制造业官网3D应用,让产品会“说话”
2025-06-23 18:26:27

互联网服务行业丨上海中商股份采购官微名片独立版,解锁员工商务社交新维度,打造全员营销获客裂变神器
2023-09-02 18:00:00

LTD342次升级 | 官微App支持知识库智能搜索 • AI写作升级创作营销内容更容易
2025-09-22 16:11:04

模板库第133次上新:4套新能源行业网站模板:打通CRM管理、工单咨询、线上调研表单等功能应用
2025-05-09 13:51:24
官微名片|企业数字化转型全员必备商务社交工具
2024-01-10 23:17:14

智能站点与传统网站在营销枢纽驱动下有何不同(附对比图)
2025-10-14 18:05:36

LTD362次升级 | 新增通用型站点,免搭建开箱即用 • 订阅领红包可自定义祝福语、支持验证手机号后领红包
2026-02-24 16:19:59

食品行业|私域留客比公域拉新便宜10倍,三关六码头靠这个官网把客户“锁”在手机里
2025-05-28 15:15:26

市场人搞赛事/活动不求人,小白也自己线上办十万人创新大赛!
2022-11-24 19:29:34

“站起来,让世界看见你”,许远东与渠道人联盟的访谈实录
2025-09-22 08:46:20

LTD258次升级 | 订单新增备注与付费附件 • 预约有详情 • 视频增分类• 商品可收藏 • 官微名片新增级数据枢纽入口
2024-01-02 16:00:38

首批“AI搭建的 AI站点”已正式投入运营了
2025-11-04 18:20:00

LTD枢纽云入选中国互联网发展30周年典型案例
2024-10-22 17:39:21

AI让官网更重要,过去1年我国独立网站数量增长了8万个,达391万
2024-12-19 12:29:06

枢纽云3D模型在制造业中生产、销售、营销中的应用
2025-06-23 18:17:24
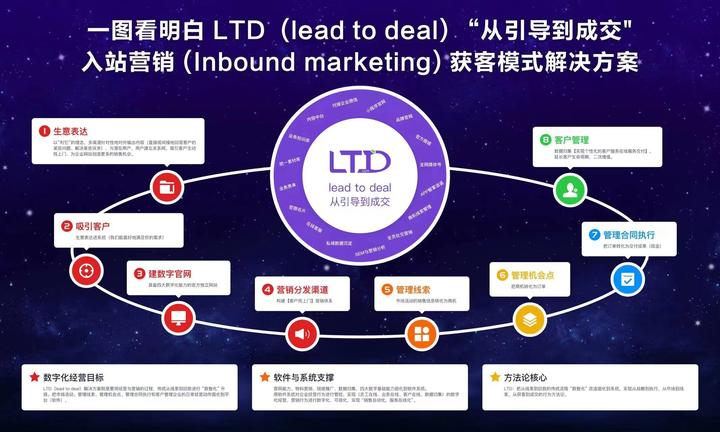
入站营销(inbound marketing)是什么?
2022-03-14 12:05:21

2024第三届22客户节暨年猪宴圆满结束!
2024-02-23 16:02:20

杭州电子商务研究院发布“枢纽型CRM”名词解释与官方定义
2025-12-11 11:53:20

它是新物种:有限的实体公司,无限的数字化未来!
2021-08-04 11:24:20

模板库第109次上新:教育美妆家居建筑机械等5套行业网站模板及多应用功能数字化网站主题风格
2024-09-09 09:50:13

生意十问十答:打造大模型信赖的AI友好型网站
2026-06-17 16:04:55

增长黑武器|LTD荣获“2022中国产业数字化技术赋能奖先锋”
2022-11-16 21:16:29

官网还没开发完,你可能就已失去了数字化的流量红利...
2022-10-31 13:48:46

LTD322次升级 | 文件下载等内容支持查看访问与下载量 • 简报短信可设置接收人 • 入站数据可识别同一访客多次访问
2025-05-06 15:44:04

基督教堂变身“知识网红”!枢纽云助力传统教堂数智化升级
2024-07-04 00:54:56





