



网络爬虫的分类及工作原理
订阅
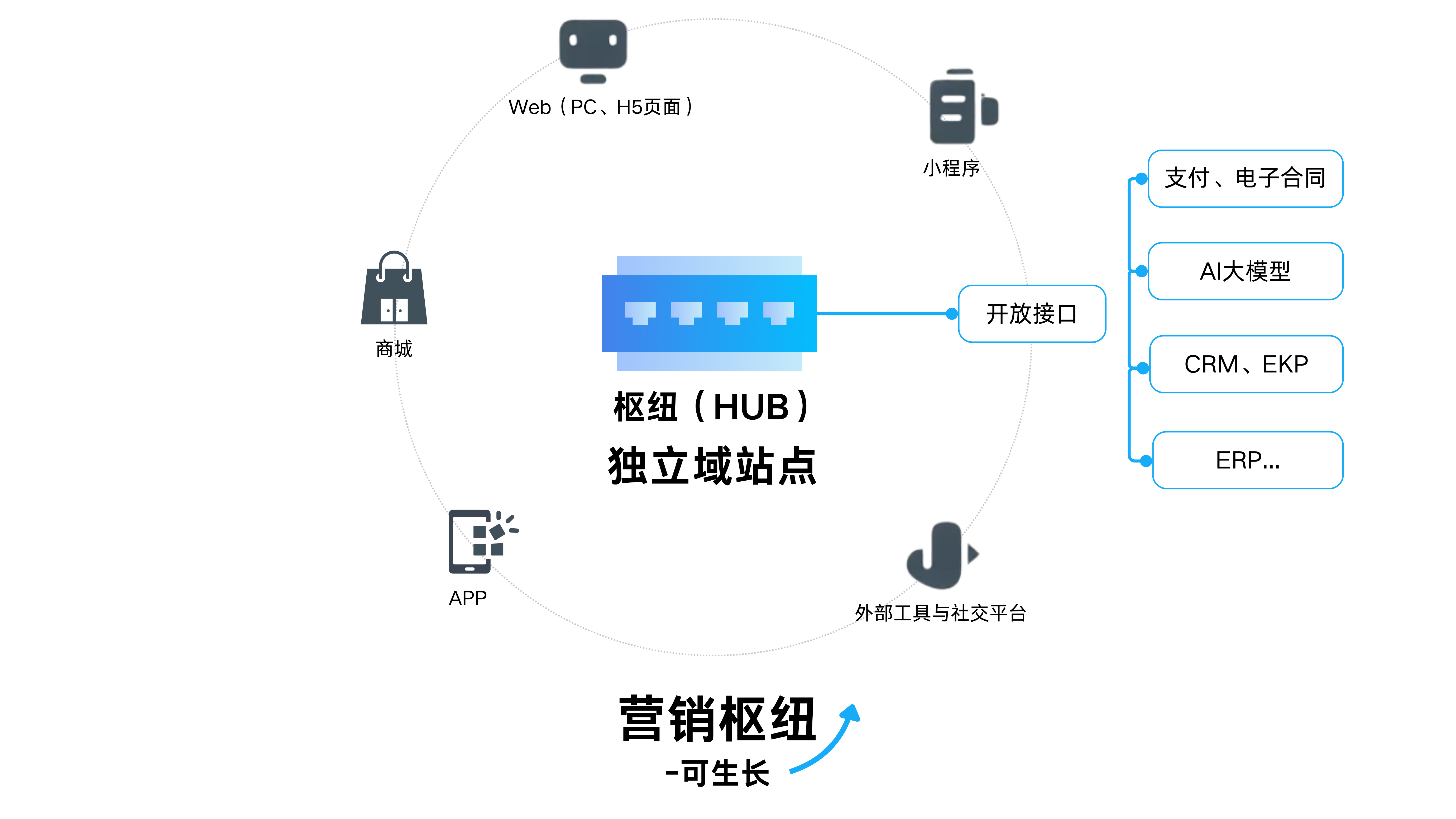
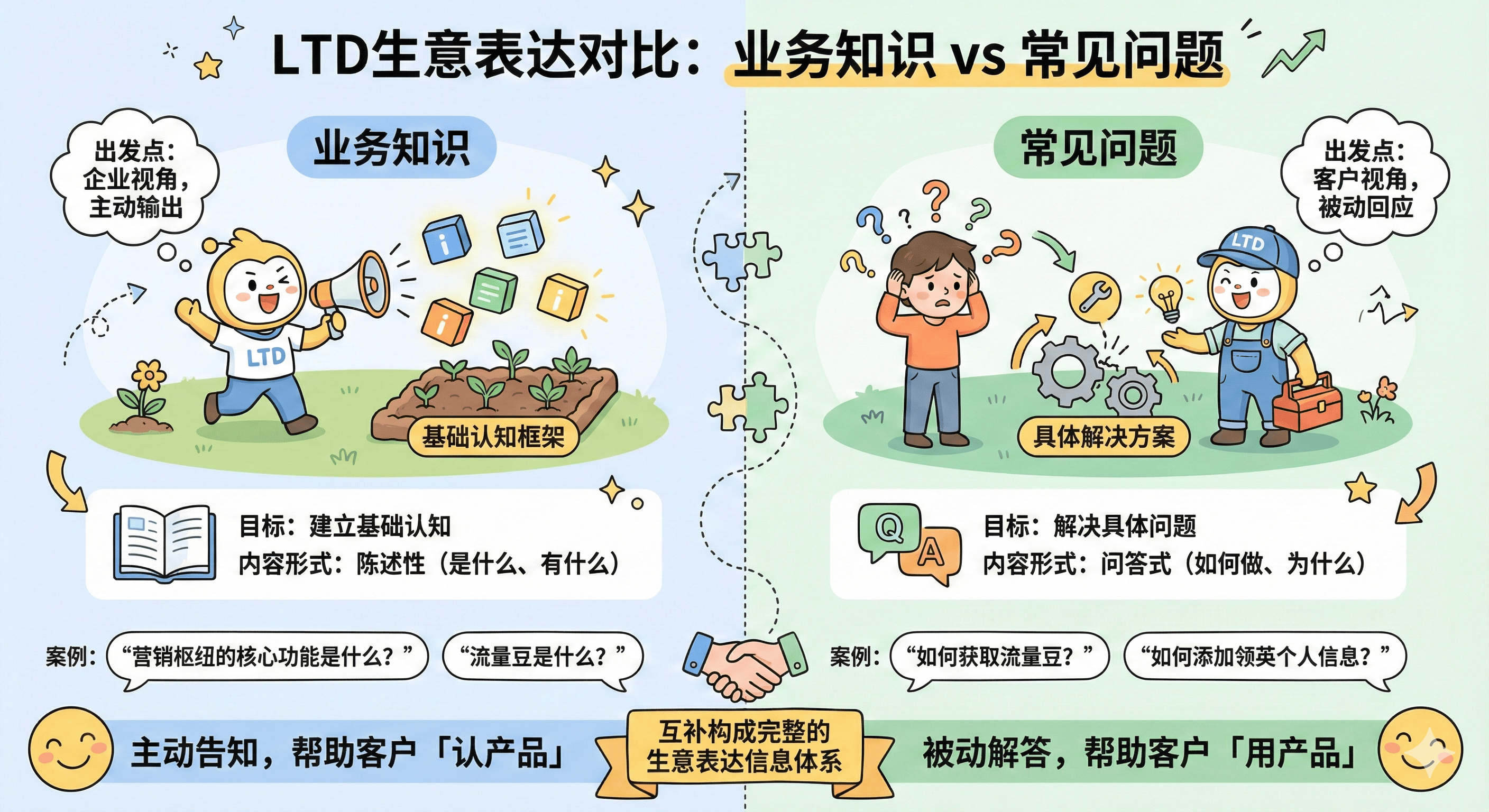
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(GeneralPurposeWebCrawler)、主题网络爬虫(TopicalWebCrawler)、深层网络爬虫(DeepW
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、主题网络爬虫(Topical Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际应用中通常是将这几种爬虫技术相互结合。通用网络爬虫根据预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获取一个URL,进而访问并下载该页面。主题网络爬虫根据预定的抓取目标,有选择地访问网页与相关的链接,获取所需信息。深层网络爬虫用于发现隐藏在普通网页中的高质量、高权威的信息,通过分析网页结构并使用一定的算法进行分类,获取更多的页面和链接。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请您通过400-62-96871或关注我们的公众号与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!
阅读全文

















请先 登录后发表评论 ~