



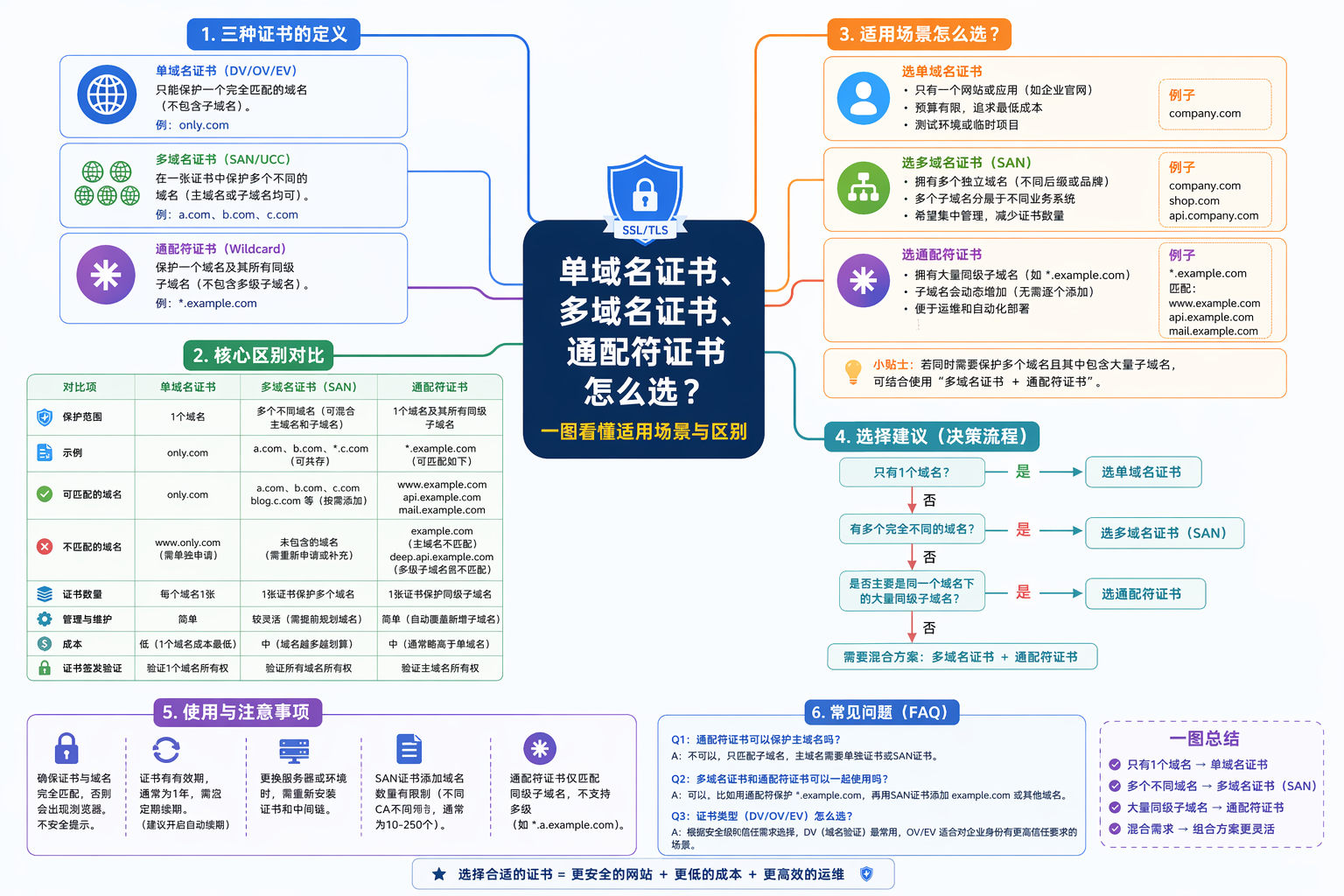
Web搜索的发展历程是怎样的?
在Web未出现之前,网络中文件传输就已经相当频繁了,为了查找大量散布在FTP主机中的文件,加拿大麦吉尔大学计算机学院的学生Alan Emtage、Peter Deutsch、Bill Wheelan等人于1990年开发了Archie软件系统。Archie系统依靠脚本程序,定期搜集并分析各个FTP站点中可下载的文件资源信息,并通过对有关信息进行索引,为用户提供检索服务。虽然Archie处理的信息资源对象与现代Web搜索系统的信息资源对象不同,但是后来的Web搜索借鉴了Archie信息搜集、建立索引、提供服务的工作方式,这也使得Archie成为现代Web搜索系统的鼻祖。
Web的出现使得依靠网页间特有的超链接关系获取信息成为可能。1993年美国内华达大学的Matthew Gray开发出World Wide Web Wanderer,成为世界上第一个利用HTML网页之间的链接关系来检测Web发展规模的“机器人”(Robot)程序,这种程序后来也被称为“蜘蛛”(Spider)或“爬行器”(Crawler)。与Archie的不同之处在于,Wanderer是利用HTML文档之间的链接关系,在Web上从一个网页“爬行”(Crawl)到另一个网页,并将爬行过的网页“抓取”(fetch)到本地进行分析。随着互联网的迅速发展,基于HTTP访问的Web技术迅速普及,到1994年初,一些基于“爬行器”原理的Web搜索工具开始涌现,其中以Jump Station、The World Wide Web Worm和Repository-Based Software Engineering (RBSE) spider最负盛名。而第一个现代意义上的搜索引擎是1994年7月由Michael Mauldin创建的Lycos,它将John Leavitt开发的蜘蛛程序接人其索引程序中,推出了基于“机器人”的数据发现技术,支持搜索结果相关性排序,并首次使用了网页自动摘要技术。在随后的几年时间里,搜索引擎如雨后春笋般涌现出来,推动了Web搜索技术的发展。1995年12月,DEC公司推出了Alta Vista搜索引擎,Alta Vista是第一个实现了自然语言检索的搜索引擎,具备了基于网页内容分析、智能处理的能力。1995年华盛顿大学硕士生Eric Selberg和Oren Etzioni开发的Metacrawler第一次实现了元搜索,通过调用其他多个搜索引擎的结果,加以整合,统一提供给用户,是元搜索引擎的开山之作。
目前,Internet上提供公开服务的各类搜索引擎已达数百家,而服务于特定目的的搜索系统则不计其数,其中,影响最大、使用最为广泛的外文搜索引擎是Google、中文搜索引擎是“百度”,前者首创了Page Rank算法,极大地提高了采集页面的质量,后者则拥有当前世界上最大的中文信息库。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请您通过400-62-96871或关注我们的公众号与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!


















请先 登录后发表评论 ~