



Robots协议的详解?
订阅
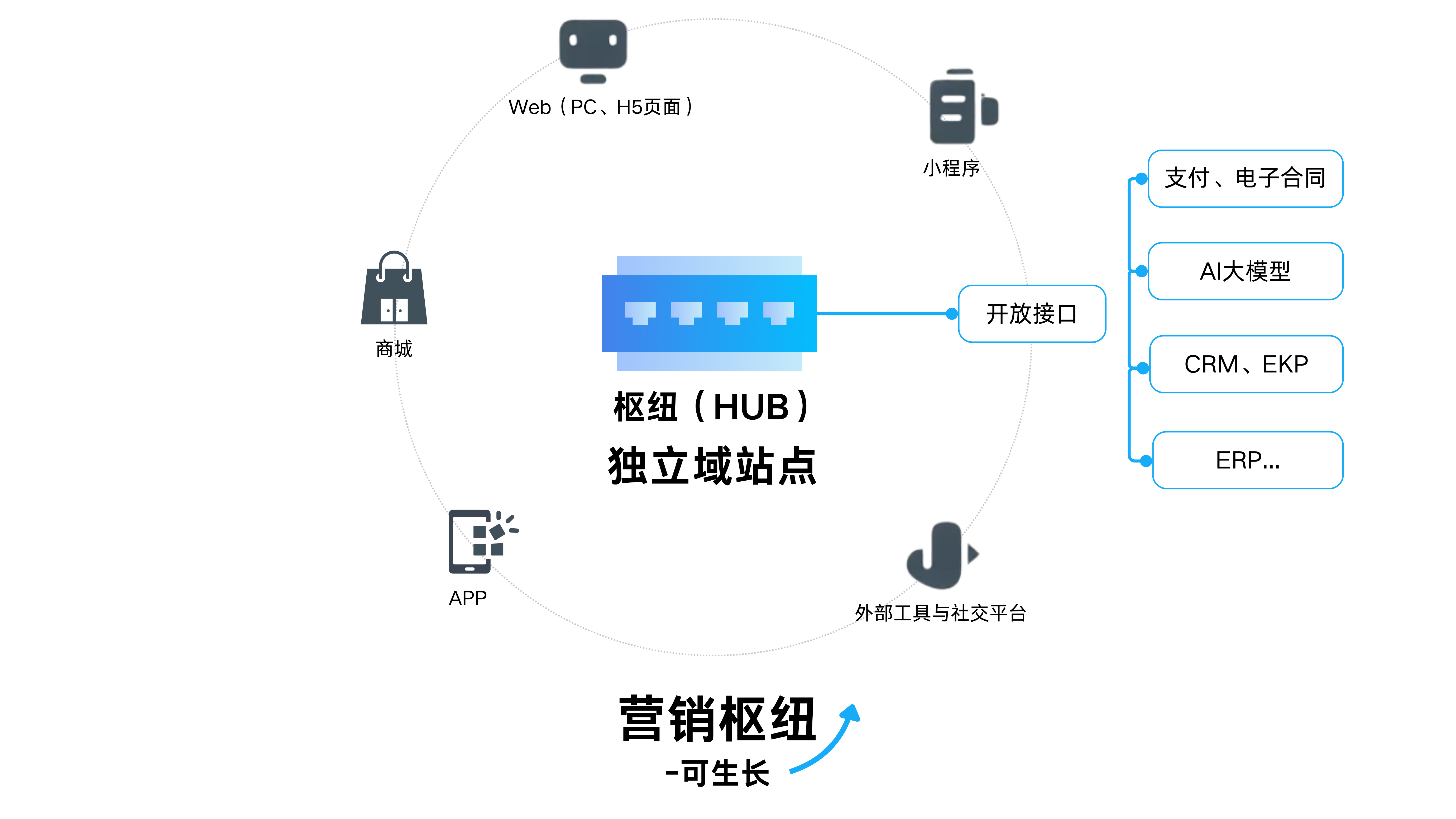
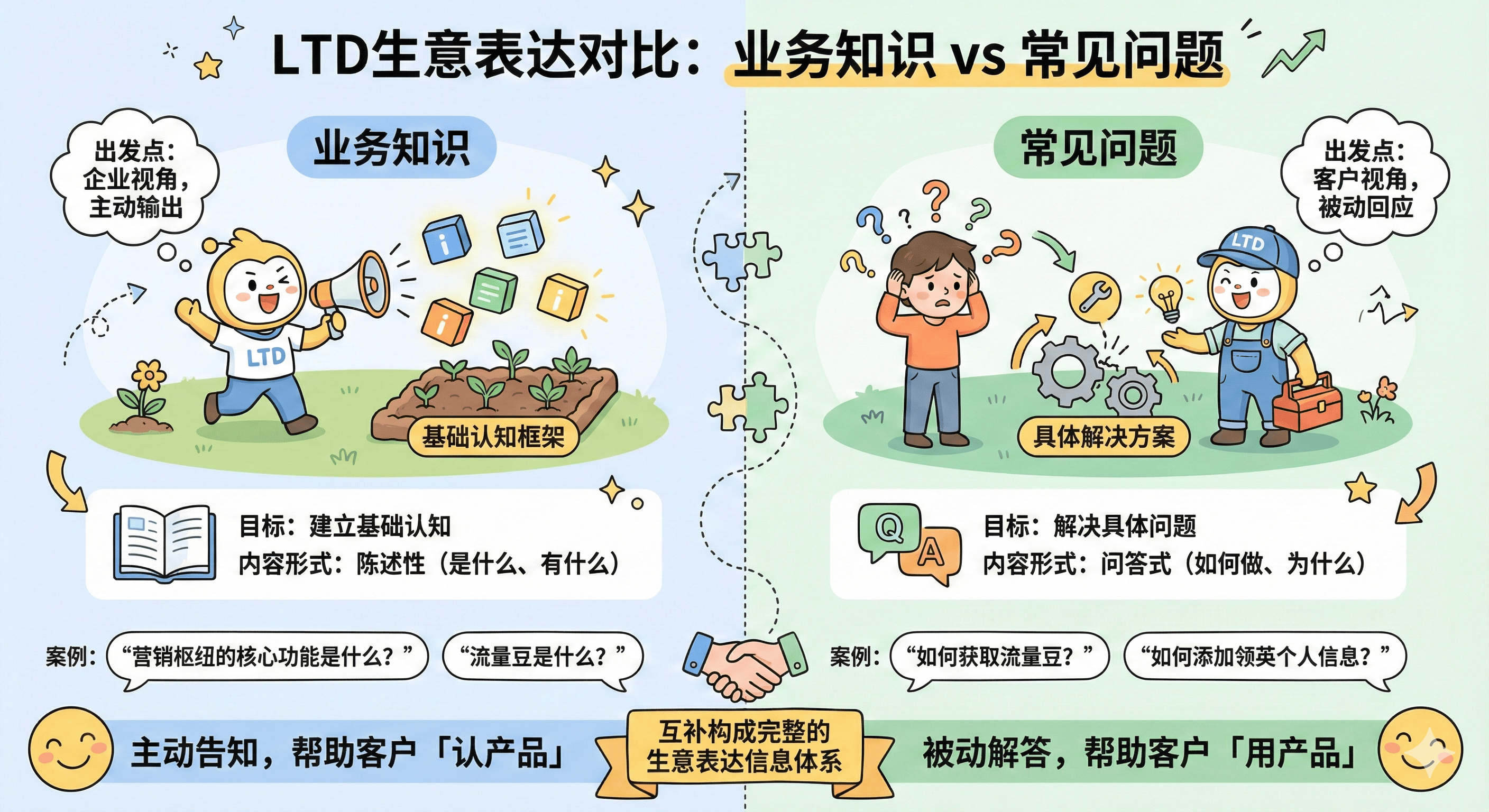
Robots协议是Web站点和搜索引擎爬虫交互的一种方式,Robots.txt是存放在站点根目录下的一个纯文本文件。该文件可以指定搜索引擎爬虫只抓取指定的内容,或者是禁止搜索引擎爬虫抓取网站的部分或全
Robots协议是Web站点和搜索引擎爬虫交互的一种方式,Robots.txt是存放在站点根目录下的一个纯文本文件。该文件可以指定搜索引擎爬虫只抓取指定的内容,或者是禁止搜索引擎爬虫抓取网站的部分或全部内容。当一个搜索引擎爬虫访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索引擎爬虫就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索引擎爬虫就沿着链接抓取。另外,robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。如果搜索引擎爬虫要访问的网站地址是http://www.w3.org/,那么robots.txt文件必须能够通过http://www.w3.org/robots.txt打开并看到里面的内容。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请您通过400-62-96871或关注我们的公众号与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!
阅读全文

















请先 登录后发表评论 ~