



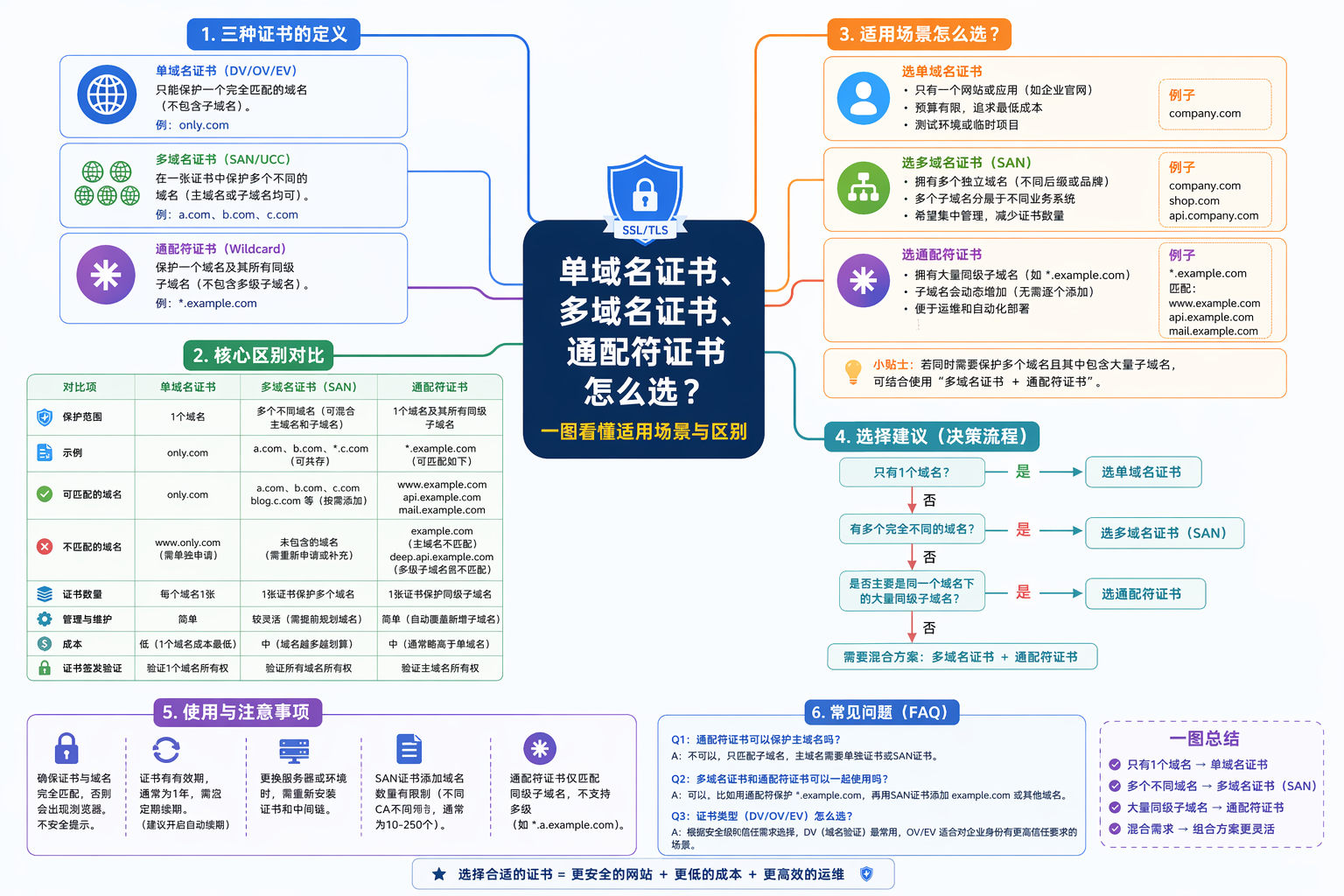
数字化背后的用户画像与行为数据处理
数字化的生活让人对信息来源产生质疑。你在微信上与朋友聊天时提到想去日本旅游,之后在朋友圈看到了机票广告,在你的老婆要求你买奶粉时,又在淘宝上看到了奶粉推荐。这些广告是如何出现的?为什么这些应用程序能够准确推荐你感兴趣的商品?淘宝并没有通过监听你的电话来获取信息,而是通过你的行为数据来判断你需要购买婴儿奶粉。注册一个账号时,你需要提供一些基本信息,例如姓名、手机号码、性别和所在地。但这些信息只是微不足道的基础数据。更重要的是,你的消费记录、打车频率、关注的公众号、玩过的游戏、理财习惯、是否有车贷房贷或购买保险以及发过的红包等行为数据最终会转化成数千个标签,成为你行为数据的一部分。采集这些标签并不难,难的是建立模型,从杂乱的标签中找到你真正的兴趣,进而构建用户画像。举个例子,你打开一篇内容标签为美女的文章,并不意味着你真的爱看美女,可能只是不小心点到。这时,就需要通过你更多的行为来判断这篇文章对你的吸引力。这是一个非常初级的内容标签权重算法:兴趣标签(美女)权重 = 行为权重 x 访问时长 x 衰减因子。行为权重对应你是否有评论、点赞、转发、收藏等操作,不同操作有不同的数值,累加成行为权重;时长权重则根据停留时间来计算,停留时间越长,时间权重也越高;衰减因子则是根据时间因素来计算,单次阅读行为的权重会随着时间流逝不断衰减。
当你打开一个包含美女类内容的应用时,算法会生成一个兴趣权重。这个权重会在一段时间内记录你所有的美女类兴趣,并用S形函数标准化,在0到10的区间内给出一个兴趣标签值。这个标签值越高,说明你对美女就越感兴趣。除了内容兴趣,这种算法思路可以在消费能力、消费兴趣和社交习惯等多个维度建立模型,计算你的偏好。之后,这些偏好会被转换为特征向量。例如,如果你的美女兴趣标签值是8,消费能力是5,社交偏好是2,那么你的特征向量可以表示为 r (8,5,2)。我们可以把特征向量理解成多维空间上的一个坐标,并通过把每一个用户的向量坐标带入余弦公式或距离公式中,计算出和你相似的人,进而把用户分类。
然而,行为数据只能计算偏好,无法判断你的性别、学历等个人属性。因此,需要把已知性别和学历的用户作为样本,一部分用来训练模型,一部分用来测试准确度。如今,各大平台对于用户性别的预测准确度已经可以达到90%以上。
最终,微信、淘宝等平台能够得到一个用户画像,包括消费水平、婚恋情况、内容兴趣和消费行为等上千个定向标签。广告主可以自由组合这些标签,最后选定广告位和投放时间,根据系统计算的建议出价,就完成了一次精准投放。当一个住在北京朝阳有过奶粉消费记录的已婚男青年在即将刷到广告位的那一瞬间,广告平台会发起竞价请求,最后,价高的广告将出现在用户面前。
如果你对这个话题感兴趣,可以在腾讯广告平台的开发者文档中,了解更多关于行为数据的处理过程,例如如何筛选出“2017.7.1至2017.7.15去过上海机场3次以上的人”,以及更多相关信息。
为什么 App 能知道你想买什么?
推荐算法的效果往往不如同类推荐商品。通过找到和你一样的人,把他们的浏览和消费记录推荐给你,可以更好地提高推荐效果。需要说明的是,微信、淘宝等应用采集的行为数据不仅仅对应你的账号,还与你的手机唯一识别码绑定在一起。在安卓手机上,可以采集到的唯一设备编码叫 IMEI,在 iPhone 上叫 IDFA。这意味着,即使你不注册不登录,你的行为数据一样会被采集。
同时,广告平台也可以根据你的手机识别码在其他应用中为你投放广告,这样,你刷抖音的时候也能看到淘宝的奶粉广告了。但是,根据《个人信息安全规范》,商业广告平台的所有标签都应该避免精确定位到个人,以保护你的隐私安全。如果你是 iPhone 用户,还可以通过在设置中关闭 IDFA 码限制应用对你的数据采集。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请您通过400-62-96871或关注我们的公众号与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!


















请先 登录后发表评论 ~