



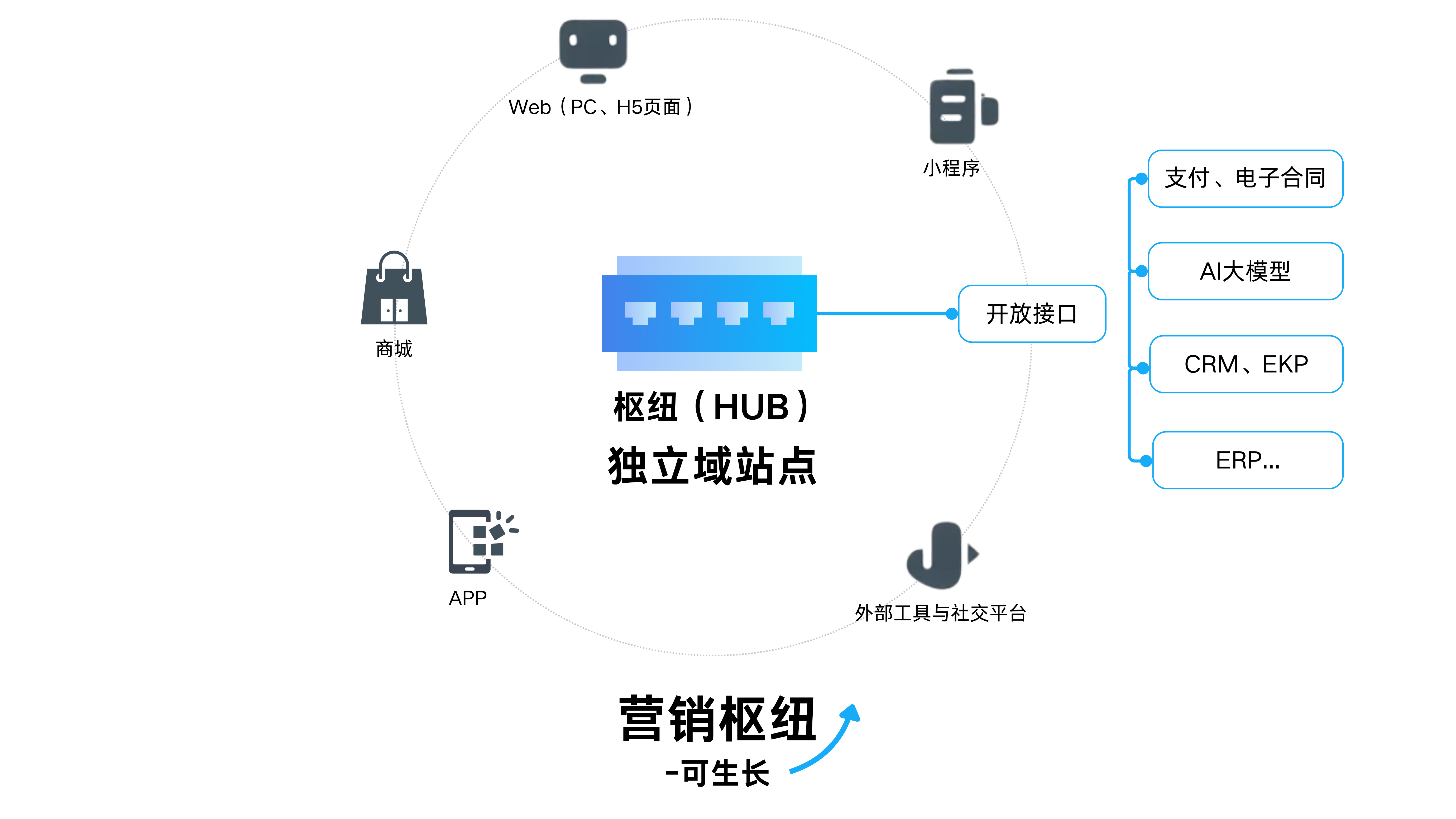
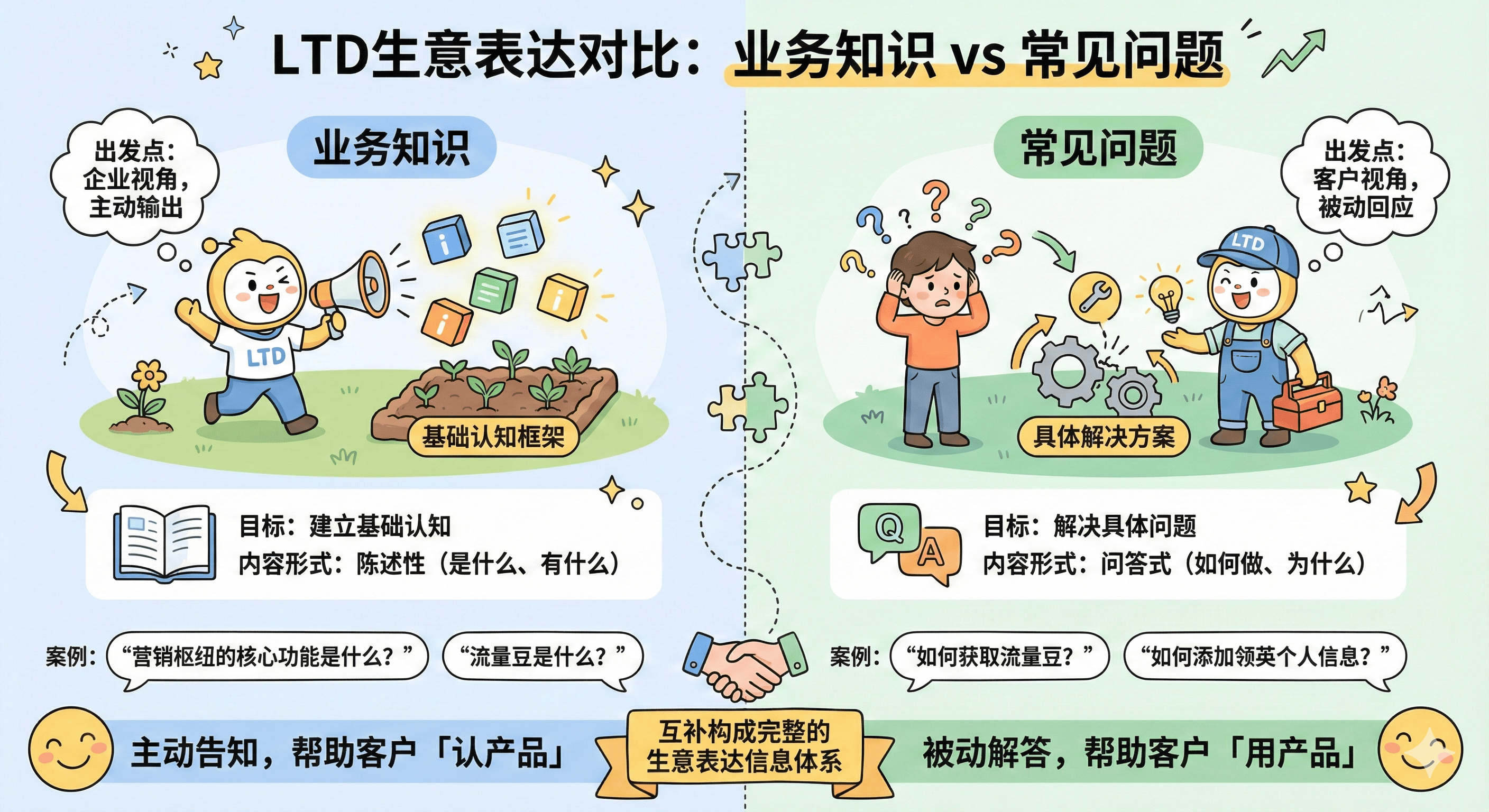
规则提取的内容?
订阅
从受训模型上提取符号规则,可以为黑匣子模型添加可理解性。规则提取技术试图打开黑匣子,生成可理解的符号描述,使之具有几乎与模型本身一模一样的预测力。用不可理解的黑匣子模型作为规则提取的入手点,比如支持向
从受训模型上提取符号规则,可以为黑匣子模型添加可理解性。规则提取技术试图打开黑匣子,生成可理解的符号描述,使之具有几乎与模型本身一模一样的预测力。用不可理解的黑匣子模型作为规则提取的入手点,比如支持向量机(SVM)或者神经网络,其好处是它们能够为更为复杂的关系建立模型。
Andrew等(995)提出了神经网络规则提取技术的分类方法,它完全可以扩大到SVM上(Matens等,2007);它是建立在如下准则之上的:
- 与深层的黑匣子模型相关的提取算法的透明度。
- 所提取的规则或者树的表达力。
- 神经网络的专门训练方法。
- 所提取规则的质量。
- 提取算法的计算复杂性。
透明度准则考虑的是该技术对黑匣子模型的认知。分解法与黑匣子模型的内在机制紧密相关。而指导型算法则是把受训模型看做黑匣子。这些算法不考察内在结构,而是直接提取与模型的输入和输出相关的规则。这些技术通常把受训模型用作训练样本的标签或者分类的评价器(人工生成),然后训练样本再被符号学习算法使用。这些技术背后的道理在于,它们假定受训模型比初始数据集能够更好地表示数据。所提取规则的表达力取决于用来表达规则的语言。文献中提出了多种类型的规则,其中最主要的有命题规则、M-of-N规则和模糊规则。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请您通过400-62-96871或关注我们的公众号与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!
阅读全文

















请先 登录后发表评论 ~