



内容运营必知的推荐流程和算法原理
不想成为“厨师”的“采购员”无法成为“优秀运营人员”。对于内容产品的运营工作来说,特别是涉及到“内容运营”的同学,与推荐算法的配合非常重要。运营同学的角色类似于餐馆的采购员,负责采购食材;而推荐同学则像是厨师,根据用户的喜好选择食材,做出用户可能会喜欢的菜肴。在这个过程中,运营同学处于上游的位置。如果引入的内容/创作者不够优质,就像采购的食材不够新鲜和高质量,无论推荐同学如何努力,都很难做出美味的菜肴。同时,还存在另一个问题,即使运营同学采购了最好的食材,如果推荐同学做菜的方式有问题,没有合理地利用食材,也不能充分发挥食材的价值,这样就是对食材的浪费。因此,对于运营同学来说,不仅要做好自己的上游工作,还非常有必要了解推荐的相关工作。这样,当菜肴的口味不佳时,我们才能及时发现是食材的问题还是做菜的方法有问题,从而更快地进行调整。
必知一:内容是如何被推荐的?
对于运营同学来说,首先需要了解的是:内容是如何被推荐的?我们引入的创作者和他们的内容,是如何经过一系列流程来决定是否被推荐以及被赋予多少流量的?虽然不同产品和公司的处理流程可能不完全相同,但整体逻辑基本相似。整个处理流程大致如下图所示。
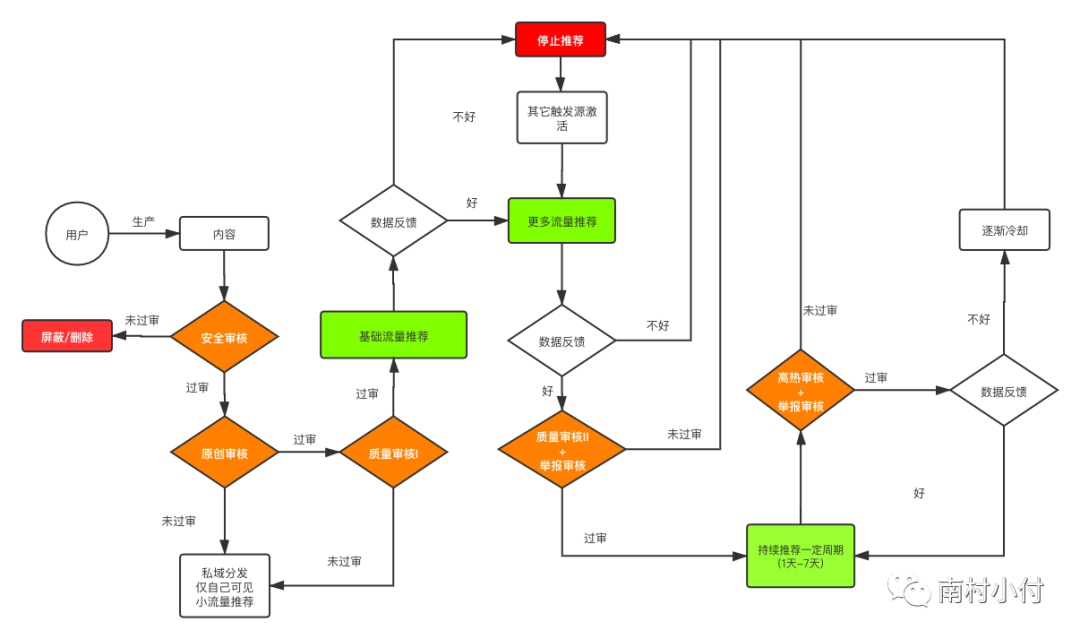
如上图所示,用户上传的内容经过安全审核后,会首先进行安全审核,主要目的是剔除违规、色情暴力等内容,未通过审核的视频基本上会被永久屏蔽或直接删除。通过安全审核后,大多数内容社区会进行原创审核,过滤掉重复上传或搬运的内容。原创审核主要依靠机器进行,未通过原创审核的内容只会在用户个人主页或粉丝的关注页等私域展示。通过原创审核的视频进入第一道质量审核,主要目的是过滤掉无意义、无主题或杂乱的内容。通过第一道质量审核后,内容会被推荐系统纳入推荐候选池,并获得基础流量推荐。这是为了通过基础流量产生的数据初步判断作品的质量好坏。如果基础流量后的数据反馈较好,会进一步增加流量推荐,如果数据表现不好,推荐会停止。数据表现好的内容会进入第二道内容质量审核或举报审核。第二道质量审核的目的是防止前面的审核漏审或出现不符合社区内容调性的内容。举报审核是指用户主动举报内容,收到过多举报的内容往往存在潜在风险,需要进行人工审核。通过第二道质量审核或举报审核后,作品会持续获得更多流量推荐,进入周期性的推荐,成为内容平台重点推荐的候选内容。在整个持续推荐过程中,还会有一些更细的审核流程,如高热审核,针对全平台最热门的视频进行审核,确保没有风险。同时,会持续进行用户举报审核,及时发现潜在违规作品。如果内容的数据反馈下滑,推荐会逐渐停止。然而,在所有流程中,被停止推荐的作品仍有可能因为偶然的触发或其他原因被重新激活,获得更多流量推荐。例如遇到节日,过往节日相关的内容会被重新推荐。通过了解上述推荐流程,运营同学就能对整体内容流转有清晰的认知,可以结合自己的产品或业务逻辑,细化整个流程。这样,在遇到问题时,就能及时知道内容处于何种阶段,从而进行及时调整。
必知二:推荐系统的工作原理
在上述推荐流程中,我们能够了解内容流转的逻辑,但在图中的流量推荐模块中,实际上并不清楚是如何进行推荐的。为了弄清楚这个问题,我们需要先对整个推荐系统有一定了解。简单来说,推荐系统主要由数据、算法和架构三个方面组成。
-
数据主要提供推荐所需的信息,包括用户和内容的特征信息,以及用户对内容的行为反馈数据等。
-
算法主要提供策略和逻辑。在海量的数据下,人工策略难以进行分析和干涉,因此需要一套算法来自动处理信息逻辑并返回推荐内容。
-
架构主要承载数据和算法的平台,对接上下游的数据和逻辑,保证系统能够稳定、实时、自动地运行。
常见的推荐系统架构如下图所示:
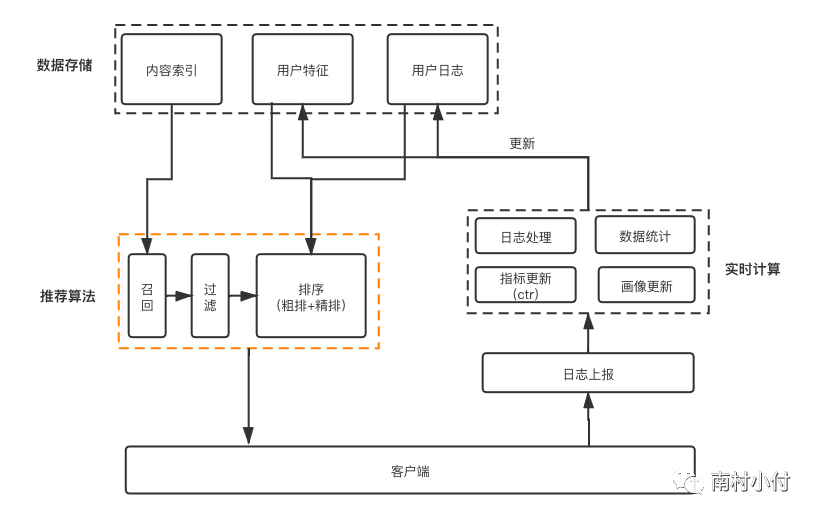
在上图的推荐架构中,数据存储模块主要负责存储内容索引(一种逻辑标识,便于查找内容)、用户特征(包括用户的画像信息、兴趣点等)和用户日志(包括用户在客户端对内容产生的行为,如点击、点赞、分享、评论等)。数据处理模块负责处理和分析这些数据,提取用户和内容的特征,生成推荐结果。推荐结果会返回给数据存储模块,然后传递给推荐展示模块,最终通过客户端展示给用户。
总的来说,推荐系统的工作原理是基于数据和算法,通过分析用户和内容的特征,以及用户行为反馈数据,生成推荐结果,并通过架构模块实现实时、稳定、自动的推荐展示。
推荐算法部分是推荐系统中的核心环节,它通过内容索引来召回候选内容,并经过过滤和排序的步骤得到最终的推荐结果。推荐算法主要包括召回和排序两个步骤。
召回是指根据一定的策略从全量内容中选取一部分候选内容。常见的召回策略包括热门召回、兴趣标签召回和协同过滤召回等。为了获得更完整、全面的召回结果,通常采用多路召回的方式。根据是否包含个性化因素来划分,召回可以分为无个性化因素和有个性化因素的召回。
排序是对召回的候选内容进行排序,以用户的特征和行为日志为依据,将内容排列成用户最有可能感兴趣的顺序。排序一般分为粗排和精排两个阶段。粗排主要是对大量的召回内容进行简单的融合排序,将候选内容控制在一个可控的数量级。精排则采用模型进行排序,将候选内容进一步缩减到百量级。
推荐结果将根据客户端的展现场景进行展示。用户对推荐内容产生的行为将通过日志上报,然后进行实时计算,更新用户画像和推荐指标,例如点击率等。计算完成后,将更新后的数据存储起来,以供后续的推荐取得最新的数据。
以上是关于推荐算法部分的内容,希望能够帮助大学毕业生更好地理解推荐系统的工作原理。如果对推荐算法感兴趣,可以参考以下书籍和文章:
-
《推荐系统实战》
-
《推荐系统》
-
推荐系统技术演进趋势:从召回到排序再到重排
-
推荐系统怎样实现多路召回的融合排序
-
【机器学习】逻辑回归
这些参考资料将进一步帮助你深入了解推荐算法的实现和发展趋势。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请您通过400-62-96871或关注我们的公众号与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!


















请先 登录后发表评论 ~